이전편 보기
샘플파일 받기
제2장 진짜 쉬운 빨강쉐이더
이 장에서 새로 배우는 HLSL
- float4: 4개의 성분을 가지는 벡터 데이터형
- float4x4: 4 X 4 행렬 데이터형
- mul(): 곱하기 함수. 거의 모든 데이터형을 변수로 받음.
- POSITION: 정점위치 시맨틱. 정점데이터 중 위치정보만을 불러옴.
이 장에서 새로 사용하는 수학
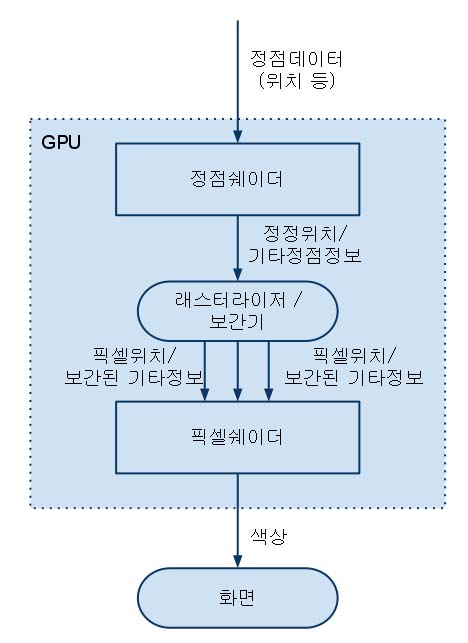
'제1장: 쉐이더란 무엇이죠?'에서 쉐이더란 픽셀의 위치와 색을 계산하는 함수라고 말씀드렸습니다. 그렇다면 이번 장에서는 실제로 픽셀의 위치와 색을 계산하는 쉐이더를 만들어봐야겠죠? 처음 쉐이더를 짜보시는 분들도 쉽게 이해하실 수 있게끔 매우 간단한 쉐이더 프로그램을 만들어 보겠습니다. 우선 렌더몽키에서 빨간색 공을 그리는 쉐이더를 작성해보면서 HLSL 문법을 처음으로 접해보는 게 좋겠군요!
(이렇게 단색을 출력하는 쉐이더는 디버깅을 할 때도 유용하게 쓰입니다.) 렌더몽키에서 쉐이더를 작성하면 그 결과를 .fx 파일로 익스포트(export)해서 이걸 DirectX 프레임워크에 그대로 가져다 쓸 수도 있습니다.
기초설정
다음의 단계를 따라서 기초적인 설정을 마무리합시다.
- 렌더몽키를 시작합니다. 무서운(?) 원숭이 얼굴이 잠시 스쳐 지나간 뒤에 빈 작업공간(workspace)가 등장할 것입니다.
- Workspace 패널 안에서 Effect Workspace위에 마우스 오른쪽 버튼을 누릅니다. 팝업 메뉴가 등장할 겁니다.
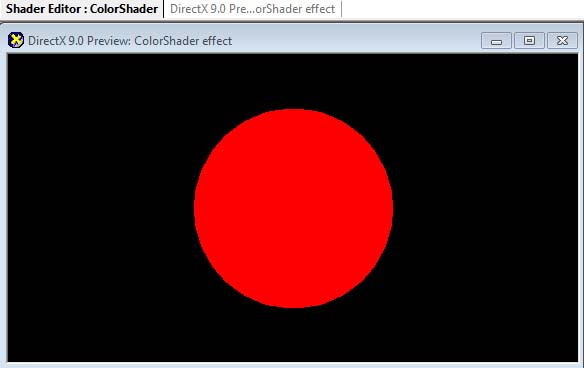
- 팝업메뉴에서 Add Default Effect > DirectX > DirectX를 선택합니다. 이제 미리 보기(preview) 창에 빨간색 공 하나가 보이죠?
- Workspace패널에 Deafult_DirectX_Effect라는 새로운 쉐이더도 추가되었을 것입니다. 쉐이더의 이름을 ColorShader로 바꿉니다.
- 이제 화면이 아래와 같을 것입니다.
 |
| 그림 2.1. 기초설정을 마친 렌더몽키 프로젝트 |
정점쉐이더
이제 ColorShader옆에 있는 더하기(+) 표시를 누릅니다. 제일 아래쪽에 Pass 0이 보이시죠? 그 옆에 있는 더하기 표시를 다시 누르세요. 이제 Vertex Shader를 더블클릭하시면 오른쪽 쉐이더 편집기 안에 Vertex Shader코드가 등장할 겁니다. 사실 여기에 들어있는 코드가 이미 빨간 공을 그리고 있지만 저희는 한 줄씩 연습을 해봐야 하니 이 속에 있는 코드를 모두 지우겠습니다.
코드를 다 지우셨나요? 그렇다면 이제 본격적으로 시작해보죠! 우선 한 눈에 보실 수 있게끔 정점쉐이더 코드를 전부 보여드린 뒤 한 줄씩 설명해 나가도록 하겠습니다.
struct VS_INPUT
{
float4 mPosition : POSITION;
};
struct VS_OUTPUT
{
float4 mPosition : POSITION;
};
float4x4 gWorldMatrix;
float4x4 gViewMatrix;
float4x4 gProjectionMatrix;
VS_OUTPUT vs_main( VS_INPUT Input )
{
VS_OUTPUT Output;
Output.mPosition = mul( Input.mPosition, gWorldMatrix );
Output.mPosition = mul( Output.mPosition, gViewMatrix );
Output.mPosition = mul( Output.mPosition, gProjectionMatrix );
return Output;
}
전역변수 vs 정점데이터
쉐이더에서 사용할 수 있는 입력 값으로는 전역변수와 정점데이터가 있습니다. 이 둘을 구분 짓는 기준은 한 물체를 구성하는 모든 정점이 동일한 값을 사용하느냐의 여부입니다. 만약 동일한 값을 사용한다면 이것은 전역변수가 될 수 있지만 각 정점마다 다른 값을 사용한다면 당연히 전역변수는 안되겠지요. 그 대신 정점 버퍼, 즉 정점 데이터의 일부로 이 값을 받아들여야 합니다.
전역변수의 예로는 월드행렬, 카메라의 위치 등이 있고, 정점데이터 변수의 예로는 정점의 위치, UV좌표 등이 있습니다.
정점쉐이더 입력데이터
우선 정점쉐이더에서 입력으로 받을 데이터들을 VS_INPUT이라는 구조체로 선언해보겠습니다.
struct VS_INPUT
{
float4 mPosition : POSITION;
};
'제1장: 쉐이더란 무엇이죠?'에서 정점쉐이더의 가장 중요한 임무는 각 정점의 위치를 공간 변환하는 것이라고 했던 거 기억하시나요? 그러기 위해서는 정점의 위치를 입력으로 받아야 하죠? 그게 바로 위 구조체가 멤버변수 mPosition을 통해 정점의 위치를 얻어오는 이유입니다. 이 변수가 DirectX의 정점버퍼
(버텍스 버퍼(vertex buffer)라고도 합니다.)로부터 위치정보를 구해올 수 있는 이유는 POSITION이라는 시맨틱(semantic,
태그(tag) 정도로 이해하시는 게 편할 겁니다.) 때문입니다. 정점버퍼에는 정점의 위치, UV좌표, 법선 등을 비롯한 다양한 정보가 담겨 있을 수 있는데 이 중에서 필요한 정보만을 쏙쏙 빼오는 것을 시맨틱이라고 해두죠.
따라서 float4 mPosition : POSITION; 이라는 코드는 '정점데이터에서 위치(POSITION) 정보를 가져와서 mPosition에 대입해라!'라는 명령입니다.
아차! 그렇다면 float4는 뭘까요? 이건 변수의 데이터형입니다. float4는 HLSL자체에서 지원하는 데이터형의 하나로 4개의 성분(x ,y, z, w)을 가지는 벡터입니다. 각 성분은 부동소수점(floating-point)형 입니다. HLSL은 float4외에도 float, float2, float3 등의 데이터형을 지원합니다.
(참고로 GPU는 부동소수점 벡터를 처리하는데 최적화된 장치입니다. 따라서 쉐이더에서 사용하는 기본적인 데이터형은 정수가 아닌 부동소수점입니다. 정수는 오히려 쉐이더의 성능을 저하시키는 요인입니다.)
정점쉐이더 출력데이터
정점쉐이더의 입력데이터를 선언해봤으니 이제 출력데이터를 살펴봐야겠죠? '제1장: 쉐이더란 무엇이죠?'에서 보여드렸던 초 간단 GPU 파이프라인의 그림을 기억하시나요? 각 픽셀의 위치를 찾아내려면 정점쉐이더가 위치변환 결과를 래스터라이저에 전달해줘야만 했습니다. 따라서 정점쉐이더는 반드시 위치변환 결과를 반환해야 합니다. 자, 그렇다면 정점쉐이더 출력데이터 구조체를 VS_OUTPUT이란 이름으로 선언해보지요!
struct VS_OUTPUT
{
float4 mPosition : POSITION;
};
float4형으로 위치데이터를 반환하면서 '이것은 위치(POSITION)요!'라는 시맨틱을 붙여준 거 보이시죠?
전역변수
정점쉐이더에서 공간 변환을 할 때, 사용해야 할 전역변수들이 몇 있는데 그 전에 공간 변환이 무언지부터 설명해 드려야 할 듯 싶군요.
3D 공간변환
3D물체를 모니터에 그리려면 정점들의 위치를 공간 변환해야 한다고 말씀드렸습니다. 그렇다면 과연 어떤 공간들을 거쳐야 3D물체를 모니터에 보여줄 수 있을까요? 사과를 예로 들어보죠.
물체공간
자, 일단 사과를 손에 쥐어봅시다. 사과의 중앙을 원점으로 삼고 그 점을 시작으로 오른쪽(+x), 위쪽(+y), 앞쪽(+z)으로 3개의 축을 만들어 볼까요? 이제 원점으로부터 사과의 표면까지의 거리를 이리저리 재보면 각 점들을 (x, y, z) 좌표로 표현할 수 있겠죠? 그리고 이 정점들을 3개씩 묶어 삼각형들을 만들면 폴리곤으로 사과모델을 만들 수 있겠네요.
이제 사과를 손에 쥔 채 팔을 이리저리 움직여봅시다. 사과를 어디로 움직이던 간에 원점으로부터 각 정점까지의 거리는 변하지 않죠? 이것이 바로 물체공간(object space) 또는 지역공간(local space)입니다. 물체공간에서는 각 물체(3D 모델)가 자신만의 좌표계를 가지므로 다수의 물체를 통일적으로 처리하기 어렵습니다.
 |
| 그림 2.2. 물체공간의 예 |
월드공간
이제 사과를 모니터 옆에 놓아볼까요? 모니터도 물체니까 자신만의 물체공간을 가지고 있겠군요. 이 둘을 통일적으로 처리하고 싶은데 그러려면 어떻게 해야 할까요? 이 두 물체를 같은 공간으로 옮겨오면 될 거 같은데요? 그러면 새로운 공간을 하나 만들어야겠군요. 현재 계신 방의 입구를 원점으로 삼고 오른쪽, 위쪽, 앞쪽으로 +x, +y, +z인 3개의 축을 만들어보죠. 이제 그 원점에서부터 모니터를 구성하는 정점들까지의 거리를 재면 새로운 (x, y, z) 좌표로 정점들을 표현할 수 있겠죠? 사과도 똑같은 방법으로 표현할 수 있겠네요. 이 새로운 공간을 월드공간(world space) 또는 세계공간이라고 합니다.
 |
| 그림 2.3. 월드공간의 예 |
뷰공간
자, 그렇다면 이제 카메라를 가져다가 사진을 좀 찍어볼까요? 일단 위 두 물체들이 모두 사진 속에 들어오도록 사진을 찍고, 다음에는 이들이 전혀 보이지 않도록 전혀 엉뚱한 곳을 찍어봅시다. 이 두 사진은 확연히 다르죠? 처음 사진에서는 두 물체를 볼 수 있는데, 다른 사진에서는 흔적도 찾아볼 수 없군요. 그렇다면 이 두 사진 간에 뭔가 위치 변화가 있어야 한단 이야긴데 월드공간에서는 그 두 물체들의 위치가 전혀 변하지 않았는걸요? 아하! 그렇다면 이 카메라가 다른 공간을 사용하는 거로군요! 이렇게 카메라가 사용하는 공간을 뷰공간(view space)이라고 부릅니다. 뷰공간의 원점은 카메라 렌즈의 정 중앙이고 역시 그로부터 오른쪽, 위쪽, 앞쪽으로 3개의 축을 만들 수 있습니다.
 |
| 그림 2.4 뷰공간의 예. 물체들이 카메라 안에 있음. |
 |
| 그림 2.5 뷰공간의 예. 물체들이 카메라 밖에 있음. |
투영공간
일반 카메라로 사진을 찍으면 인간의 눈을 통해 보는 것과 마찬가지로 멀리 있는 물체는 조그맣게 보입니다. 근데 왜 우리 눈이 이렇게 작동하는지 아세요? 이건 인간의 시야가 좌우로 각각 100도 정도, 상하로 각각 75도 정도 되어서 그렇습니다. 따라서 멀리를 바라볼 수록 눈에 들어오는 범위가 넓어지는데 이 늘어난 범위를 일정한 크기의 망막에 담으려다 보니 멀리 있는 물체가 작게 보이는 거지요. 일반 카메라도 사람의 눈을 흉내 내는데 이와는 달리 직교카메라란 것도 있습니다. 직교카메라는 상하좌우로 퍼지는 시야를 가지지 않습니다. 무조건 앞쪽만 바라보지요. 따라서 직교카메라를 사용하면 거리에 상관없이 물체의 크기가 변하지 않습니다.
그러면 결국 카메라로 사진을 찍는 과정을 두 단계로 나눌 수 있는 것 같네요. 첫째는 월드공간에 있는 물체들을 카메라 공간으로 이동, 회전, 확대/축소시키는 단계고요, 둘째는 이렇게 새로운 공간에 위치된 물체들을 2D 이미지 위에 투영하는 것입니다. 이러면 첫 번째 단계를 뷰공간, 두 번째 단계를 투영공간이라고 확실히 구분할 수 있겠죠? 이제 직각투시법(orthogonal projection)을 사용하던 원근투시법을 사용하던 간에 뷰공간은 아무 영향을 받지 않겠네요. 그 대신 투영공간에서 이 투시법을 적용하겠죠.
이렇게 투영까지 마친 결과가 바로 화면에 보여지는 최종 이미지입니다.
정리
3D 그래픽에서 정점위치의 공간을 변환할 때 흔히 사용하는 방법이 정점의 위치벡터에 공간행렬을 곱하는 것입니다. 물체를 지역공간에서 화면공간까지 옮겨올 때 거치는 공간이 총 셋(월드공간, 뷰공간, 투영공간)이므로 행렬도 3개를 구해야 합니다. 참고로 각 공간의 원점과 세 축을 알면 그 공간을 나타내는 행렬을 쉽게 만들 수 있습니다.
(이 행렬을 직접 만드는 방법은 3D 수학책을 참조하시기 바랍니다. 이 책에서는 Direct3D에서 제공하는 함수를 사용해서 이 행렬들을 구성합니다.)
자, 그럼 여태까지 논한 모든 공간변환들을 정리해서 보여드리면 다음과 같습니다.
물체공간 ----------> 월드공간 --------> 뷰공간 ---------> 투영공간
ⅹ월드행렬 ⅹ뷰행렬 ⅹ투영행렬
위의 모든 행렬들은 각 정점마다 값이 변하지 않으니 전역변수로 선언하기에 적합하군요.
전역변수 선언
그럼, 이제 어떤 전역변수들이 필요한지 아시겠죠? 그렇습니다. 공간변환을 할 때 사용할 월드행렬, 뷰행렬, 투영행렬이 필요합니다. 정점쉐이더 코드에 다음의 세 라인을 삽입합시다.
float4x4 gWorldMatrix;
float4x4 gViewMatrix;
float4x4 gProjectionMatrix;
float4x4라는 새로운 데이터형이 나왔군요? 이것도 역시 HLSL에서 지원하는 데이터형 중에 하나입니다. 4 X 4 행렬이라는 거 쉽게 아시겠죠? 이 외에도 float2x2, float3x3 등의 데이터형이 있습니다.
자, 그럼 이제 행렬들도 선언했는데 과연 누가 이 변수들에 값을 전달해줄까요? 보통 게임에서는 그래픽 엔진에서 전역변수들의 값을 대입해주는 코드가 있습니다. 렌더몽키에서는 변수시맨틱(variable semantic)을 통해 변수 값을 대입해줍니다. 그럼 변수시맨틱을 사용해보죠.
- Workspace 패널 안에서 ColorShader를 찾아 마우스 오른쪽 버튼을 누릅니다.
- 팝업메뉴에서 Add Variable > Matrix > Float(4x4)를 선택합니다. f4x4Matrix란 이름의 새로운 변수가 추가될 겁니다.
- gWorldMatrix로 변수의 이름을 변경합니다.
- 이제 gWorldMatrix 위에 마우스 오른쪽 버튼을 눌러, Variable Semantic > World를 선택합니다. 이게 바로 렌더몽키에서 변수 시맨틱을 통해 변수 값을 전달하는 방법입니다.
- 이제 위의 과정을 반복하여 뷰 행렬과 투영행렬을 만듭니다. 변수 명을 각각 gViewMatrix와 gProjectionMatrix를 만들고 View와 Projection 변수시맨틱을 대입합니다.
- 마지막으로 matViewProjection이란 변수를 지웁니다. 처음 이펙트를 만들 때 같이 딸려온 변수인데 저희는 이 대신 gViewMatrix와 gProjectionMatrix를 씁니다.
이 과정을 마치셨다면 Workspace 패널이 아래 그림처럼 보일 겁니다.
 |
| 그림 2.6. 변수시맨틱을 대입한 뒤의 Workspace 패널 |
정점쉐이더 함수
이제 모든 준비작업이 끝났습니다. 드디어 정점쉐이더 함수를 작성할 때가 왔군요. 우선 함수헤더부터 볼까요?
VS_OUTPUT vs_main( VS_INPUT Input )
{
이 함수헤더가 의미하는 바는 이와 같습니다.
- 이 함수의 이름은 vs_main이다.
- 이 함수의 인수는 VS_INPUT 데이터형의 Input이다.
- 이 함수의 반환값은 VS_OUPUT 데이터형이다.
C에서 함수를 정의하는 것과 별 차이가 없죠? HLSL은 C와 비슷한 문법을 사용한다고 전에 말씀드렸습니다. 자, 그럼 다음 라인을 보죠.
VS_OUTPUT Output;
이건 그냥 함수의 끝에서 반환할 구조체를 선언한 것 뿐입니다. 함수헤더에서 선언했다시피 데이터형이 VS_OUTPUT인 거 보이시죠? VS_OUTPUT의 멤버로는 무엇이 있었죠? 투영공간으로 변환된 mPosition이 있었죠? 그럼 이제 공간변환을 해볼 차례군요! 우선, Input.mPosition에 담긴 모델공간 위치를 월드공간으로 변환합시다. 공간변환을 어떻게 한다고 했었죠? 정점위치에 행렬을 곱하는 거였네요. 그러면 float4형의 위치벡터와 float4x4 행렬을 곱해야겠네요? 행렬과 벡터를 곱하는 법을 찾기 위해 수학책을 뒤지실 필요는 없습니다. HLSL은 이미 여러 데이터형 간의 곱셈을 처리해주는 내장함수 mul()을 가지고 있습니다. 이 함수를 사용하면 공간변환이 이렇게 간단해집니다.
Output.mPosition = mul( Input.mPosition, gWorldMatrix );
위의 코드는 모델공간에 존재하는 정점위치(Input.mPosition)에 월드행렬(gWorldMatrix)를 곱해서 그 결과(월드공간에서의 위치)를 Output.mPosition에 대입합니다. 이제 똑같은 방식으로 뷰공간과 투영공간으로 변환하면 됩니다.
Output.mPosition = mul( Output.mPosition, gViewMatrix );
Output.mPosition = mul( Output.mPosition, gProjectionMatrix );
복잡한 거 하나도 없죠? 자, 이제 무슨 일이 남았을까요? 정점쉐이더의 가장 중요한 임무는 모델공간에 있는 정점의 위치를 투영공간까지 변환하는 것이었으니까... 음.... 그 중요한 임무를 방금 막 마친 듯 한데요? 자, 그럼 이 결과를 반환하는 걸로 정점쉐이더를 마치겠습니다.
return Output;
}
이제 F5를 눌러서 정점쉐이더를 한 번 컴파일 해보면 여전히 빨간 공이 보이죠? 그럼 일단 정점쉐이더는 잘 마무리가 된 듯 하네요. 혹시라도 컴파일 에러가 보이면 뭔가 잘못했단 이야기니 한번 코드를 다시 검토해보세요.
팁: 쉐이더 컴파일에 실패한 경우
오타나 문법적 오류 때문에 쉐이더 컴파일에 실패한 경우, 미리 보기 창에 컴파일에 실패했다는 오류메시지가 등장할 것입니다. 이 때, 정확히 어떤 코드에 문제가 있는지 알고 싶으시다면 렌더몽키의 젤 아래쪽에 위치한 출력(output)창을 보세요. 자세한 오류메시지와 더불어 문제가 있는 코드의 행과 열 번호까지도 보여줍니다.